Eine einheitliche User Experience über mehrere Gerätetypen hinweg ist nicht einfach umzusetzen. Für das Image Resizing eignen sich Microservices auf Basis von Function-as-a-Service hervorragend. Folgendes Beispiel stellt in zwei Beiträgen einen auf AWS Lambda-basierenden Image-Resizer vor, der On the Fly arbeitet.
Zugegeben: Ein Image-Resizer ist quasi das Parade-Beispiel für den Einstieg in AWS Lambda. Daher haben zahlreiche Lambda-Tutorials bei AWS selbst oder Github eine solche Größenanpassung zum Thema. Zwei lohnenswerte Beispiele auf Github sind z. B. der Serverless Image Processor oder Lambda Resize Image.
In der grafischen Lambda-Console findet sich im Serverless App Repository z. B. der „image-resizer“. Wer einen solchen Service „in production“ betreiben möchte, dem empfiehlt AWS die Verwendung des Serverless Image Handlers, eine sogenannte „AWS Solution“. Dies sind von eignen Solution Architects erstellte und getestete CloudFormation-Vorlagen, die sich mit wenig Aufwand bereitstellen und einsetzen lassen.
Freilich besteht ein Unterschied zwischen einer einzelnen Lambda-Funktion als Microservice und einer voll funktionsfähigen serverlosen Anwendung. In diesem Tutorial präsentieren wir einen Entwurf für einen Image-Resizer, der sich von den Standard-Beispielen insofern abhebt, dass er „on-the-fly“ arbeitet, also direkt in den Anwendungsworkflow eingearbeitet ist, wozu der Dienst andere AWS-Dienste wie S3 und API Gateway integriert.
Die Idee basiert auf einen Blog-Eintrag im AWS Compute Blog. Der Code ist Open Source und im Github-Repo der Amazon Web Services Labs zu finden. Wir zeigen aber im zweiten Teil dieses Beitrags, wie man den Service Schritt für Schritt manuell aufbaut.
Größenänderung „On the fly“
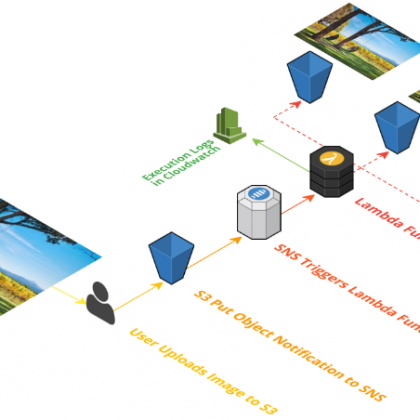
Allen oben beschriebenen Lösungen haben gemein, dass die zu konvertierenden Bilder auf Amazon S3 hochgeladen werden und die S3-Ereignisbenachrichtigungsfunktion jeweils eine Lambda-Funktion triggert, womit sich ein Service realisieren lässt, der sozusagen „auf Vorrat“ jedes auf dem überwachten S3-Bucket hochgeladene Bild konvertiert, wenn es hochgeladen wird.
Der von uns vorgestellt Ansatz arbeitet hingegen „lazy“ und erstellt ein Asset mit geänderter Größe nur dann, wenn ein Benutzer diese bestimmte Größe anfordert. Anstatt also Bilder beim Hochladen zu verarbeiten und in alle potenziell erforderlichen Größen zu ändern, bietet der Ansatz, Bilder im laufenden Betrieb zu verarbeiten eine erhöhte Agilität, reduziert die Storage-Kosten und ist extrem widerstandsfähiger gegen Ausfälle. Was bedeutet das im Einzelfall?
Vorteile des On-the-Fly-Ansatzes
Überarbeitet etwa ein Entwickler seine Website, kann er schnell und einfach neue Dimensionen hinzufügen, anstatt das gesamte Archiv der gespeicherten Bilder erneut zu verarbeiten. Letzteres ist z. B. im Rahmen eines Batch-Prozesses in jedem Fall zeitaufwändig, kostspielig und fehleranfällig.
Mit unserem On-the-Fly-Ansatz können Entwickler stattdessen einen neuen Satz von Dimensionen angeben und einfach neue Assets in dem Moment generieren, in dem der Kunden die neue Website oder Anwendung nutzt. Ferner müssen die veränderten Bilder beim herkömmlichen Verfahren unbegrenzt gespeichert werden, da der Vorgang ja nur einmal ausgeführt wird. Beim On-the-Fly-Ansatz müssen Entwickler überhaupt keine Bilder speichern, die nicht vom Nutzer zugegriffen/angefordert werden.
Der On-the-Fly-Ansatz ist außerdem robuster. Dazu ein Beispiel: so helfen bekanntlich S3-Lebenszyklus-Regeln – etwa für automatisierten Ablaufdaten älterer Bilder – bei der Kosten-Optimierung, indem die Speicherkosten an die spezifischen Zugriffsmuster einer Anwendung angepasst sind, im Extremfall bis zum Ablauf. Versucht aber nun ein Benutzer auf ein Bild mit geänderter Größe zuzugreifen, das durch eine Lebenszyklusregel entfernt wurde, ändert die API automatisch die Größe, um die Anforderung dennoch zu erfüllen.
Widerstandsfähigkeit
Ein Best Practice-Ansatz im Cloud-Computing (nicht nur bei AWS) besteht bekanntlich darin, verteilte Dienste stets so zu entwerfen, dass man den möglichen Ausfall sämtlicher Komponenten von Vorneherein einkalkuliert. In unserem Beispiel heißt das: wird die Bildverarbeitung nur einmal bei der Objekterstellung ausgeführt, kann ein zeitweiliger Fehler in diesem Prozess oder ein Datenverlust bereits der verarbeiteten Bilder zu Fehlern für zukünftige Benutzer führen.
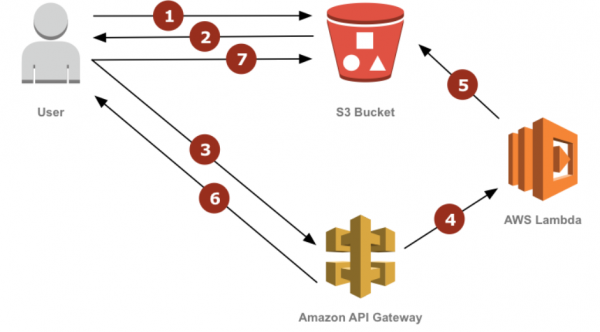
Ändert man die Größe von Bildern jedoch erst bei Bedarf, leitet jede Anforderung die Verarbeitung ein, sobald kein Bild mit passender Größe gefunden wird. Das bedeutet, dass zukünftige Anforderungen auch nach früheren Fehlern nichts ins Leere laufen. Folgende Abbildung illustriert, wie der Prozess in Gänze abläuft: