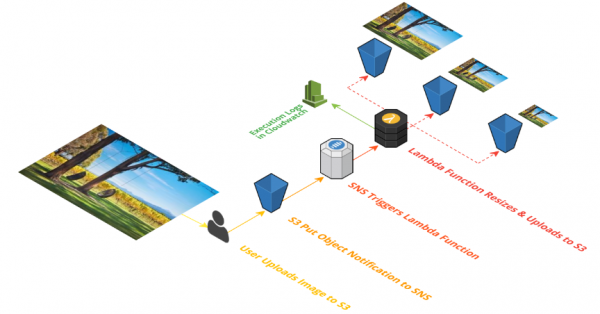
Ein auf AWS Lambda basierender Image-Resizer, der On-the-Fly arbeitet, bietet mehr Zuverlässigkeit und Agilität als eine herkömmliche Bildanpassung. Dieser zweite Teil unseres Praxisbeispiels demonstriert die Umsetzung mit AWS Lamda, API Gateway und Amazon S3.
Der komplette quelloffene Code des Beispiels wird übrigens wie im Teil 1 erläutert von AWS auf GitHub im Repo awslabs/serverless-image-resizing bereitgestellt. Wer den Service einfach nur nutzen und nicht zu Lernzwecken nachvollziehen möchte kann die benötigten Ressourcen erstellen, indem er den Anweisungen in der README-Datei folgt.
Hierbei wird eine AWS-SAM-Vorlage (AWS Serverless Application Model) verwendet. Wir erstellen die benötigten Ressourcen in diesem Tutorial allerdings manuell. Wir beginnen mit dem S3-Bucket. Das Erstellen eines Buckets in der S3-Console sollte jedem Entwickler geläufig sein. Buckets sind regional angelegt, der Bucket-Name (Namespace) muss aber global unique sein.
Wichtig ist, dass man bei den Bucket-Berechtigungen nicht pauschal öffentlichen Zugriff via Bucket-ACL erlaubt, sondern im Tab „Permissions“ eine Bucket-Policy für anonymen Zugriff einrichtet. Das benötigten Policy-Dokument in JSON kann man entweder per Policy Editor erzeugen, von Grund auf neu in den Policy-Editor eingeben oder einfach folgende Policy-Vorlage von AWS verwenden. Man muss dann lediglich den Bucket-Namen anpassen.
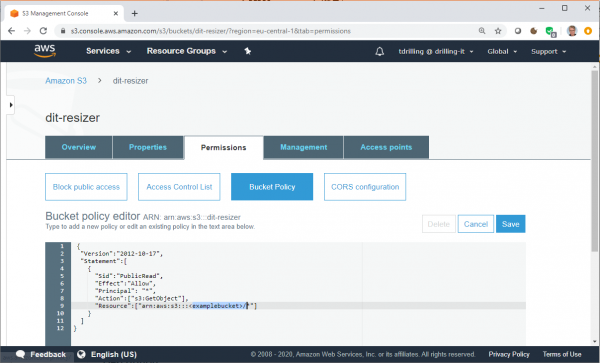
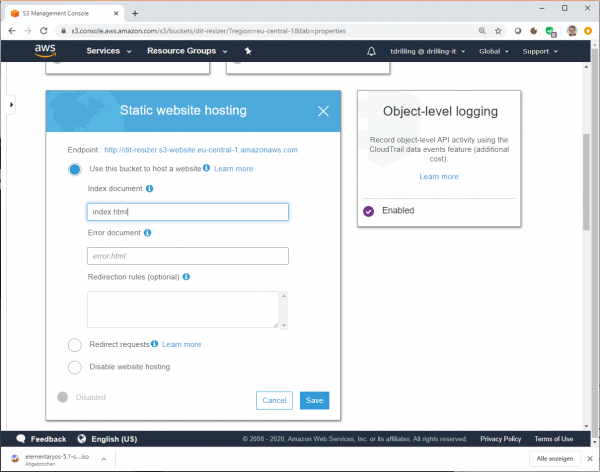
Darüber hinaus muss man im Tab „Properties“ das Feature „Static website hosting“ aktivieren und dabei als „Index document“ index.html eintragen. Nach dem Speichern notiert man sich bei der Gelegenheit gleich den Namen des Website-Endpunkts ganz oben hinter „Endpoint:“.
Lambda-Funktion
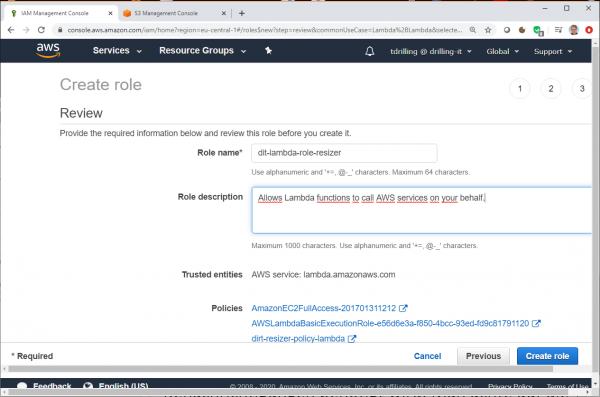
Weiter geht es mit der Lambda-Funktion. Wir haben schon öfter demonstriert, wie man in der grafischen Lambda-Console eine neue Lambda-Funktion wahlweise vom Reißbrett, per Blueprint, Herunterladen des Codes von S3 oder Hochladen eines ZIPs anlegt. Um die Ausführungsrollenberechtigungen für die Funktion zu definieren, wählen wir im Abschnitt „Permissions“ bei „Choose or create an execution role“ die Option „Use an existing role“.
Hier wählen wir dann die zuvor in IAM für den Lambda-Service erstellte Rolle. Wie das geht, haben wir ebenfalls schon häufiger demonstriert.
Der JSON-Code für Richtlinien-Dokument sollte so aussehen, wobei der Bucket-Name wieder durch den eigenen zu ersetzen ist.
{
„Version“: „2012-10-17“,
„Statement“: [
{
„Effect“: „Allow“,
„Action“: [
„logs:CreateLogGroup“,
„logs:CreateLogStream“,
„logs:PutLogEvents“
],
„Resource“: „arn:aws:logs:*:*:*“
},
{
„Effect“: „Allow“,
„Action“: „s3:PutObject“,
„Resource“: „arn:aws:s3:::<examplebucket>/*“
}
]
}
Für den Lambda-Function-Code selbst verwenden wir das von AWS bei Github bereitgestellte Code-Sample. Dieses laden wir vorher lokal herunter und stellen es dann im GUI-Dialog zur Bereitstellung einer neuen Lambda-Funktion als ZIP bereit. Die Runtime ist NodeJS. Als Trigger der Lambda-Funktion (Integration) nehmen wir nicht S3, sondern API-Gateway.
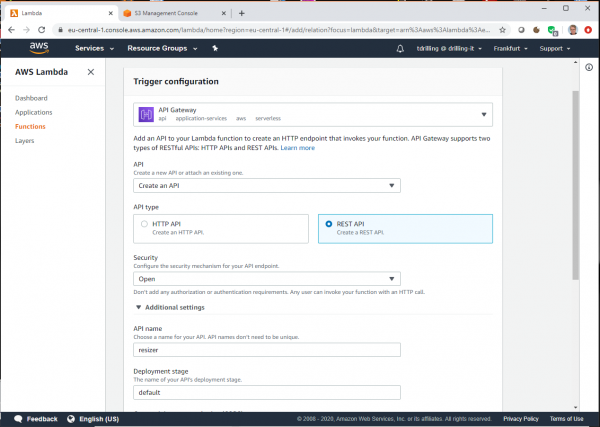
Bei „API“ wählen wir „Create an API“ und bei „Security“ den Eintrag „Open“. Der API-Type ist „REST-API“. Dies erlaubt es Usern, die API-Methode aufzurufen. Der API-Name muss in diesem Fall „resizer“ lautet, damit der Trigger mit dem Code-Sample für die Lambda-Funktion zusammenpasst. Dann klicken wir auf „Add“. Den Stage ändern wir von „default“ auf „prod“.
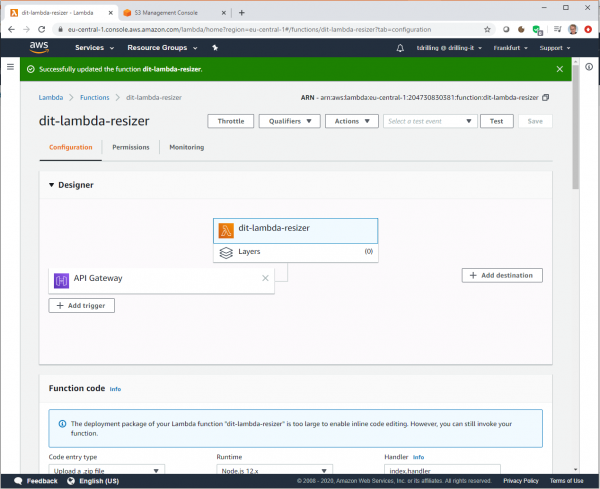
Im Designer sieht die Lambda-Funktion dann aus wie im vorangestellten Bild. Jetzt markieren wir in der Designer-Übersicht den mit lila Icon gekennzeichneten Trigger „API-Gateway“ und notieren uns dann im aufpoppenden Bereich „API-Gateway“ den kompletten Pfad zum API-Endpunkt (API Endpoint), in unserem Beispiel lautet er: https://umb19y0ck8.execute-api.eu-central-1.amazonaws.com/default/dit-lambda-resizer.
Etwas weiter unten im Lambda-Dialog müssen wir dann noch zwei Umgebungsvariablen hinzufügen. Hierzu klickt man bei „edit envrionment variables“ auf die Schaltfläche „Edit“ und dann auf „Add envrionment variables“. Die beiden benötigten Schlüssel geben wir im Punkt „BUCKET“ mit dem erstellten Bucket-Namen als Wert sowie in „URL“ mit dem oben angegebenen S3-Website-Endpunkt an.
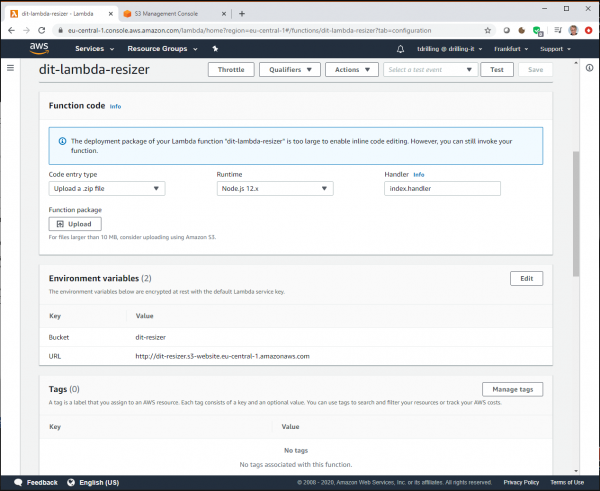
Dann wählen wir in den „Basic settings“ noch als Arbeitsspeicher den Wert 1536 aus und wählen ein Zeitlimit von zehn Sekunden. Dann speichern wir sämtliche Einstellungen für die Lambda-Funktion und den Trigger.