Im Rahmen einer Data-Lake-Strategie sind mehrere Möglichkeiten vorstellbar, wie die zu verarbeitenden Daten nach AWS S3 gelangen. Soll oder muss dies in Echtzeit erfolgen, ist eine verwaltete Streaming-Lösung wie AWS Kinesis eine gute Wahl. Dann muss nur noch die Frage beantwortet werden, wie man die Daten mit einem Index versieht.
In den folgenden Demonstrationen setzen wir einige der grundlegenden Services zum Erstellen eines serverlosen Data Lake in AWS auf. Zur Erinnerung: per Definition ermöglicht eine Data-Lake-Lösung in der Cloud eine kontinuierliche und skalierbare Datenaufnahme und Speicherung.
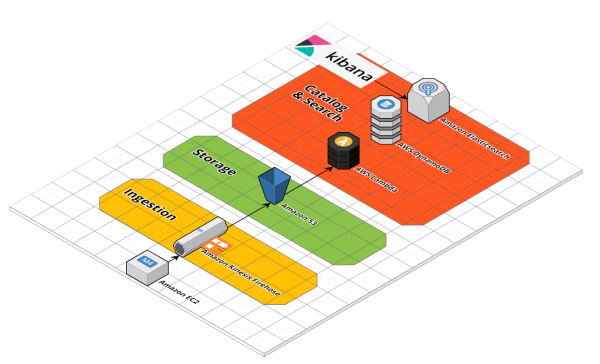
Gleichzeitig bietet der Data Lake einen Katalog/Index von Metadaten in einer permanenten Datenbank als Startpunkt für die nachgelagerte Verarbeitung. In Summe entsteht daraus eine vollständige Datenanalyse-Lösung. Der Data Lake stellt dabei drei Kernfunktions-Ebenen „Ingest“, „Speicherung/Lagerung“ sowie „Index und Suche“ bereit.
AWS Kinesis Data Firehose
Ein möglicher Ansatz des Baukasten-Prinzips von AWS besteht darin, für den Datenaufnahme-Layer Amazon Kinesis Data Firehose bzw. einen Firehose-Delivery-Stream zu verwenden. AWS Kinesis Data Firehose stellt Nutzern eine zuverlässige Methode zum Laden von Stream-Daten in einen Datenspeicher wie S3 und bei Bedarf zusätzliche Analyse-Tools zur Verfügung.
Firehose und S3
Schicht 1 unseres Data Lake besteht aus Kinesis Firehose und S3. Dazu benötigen wir ein S3-Bucket für unseren Data Lake, der in der Management Console schnellt erstellt ist. Als nächstes benötigen wir einen Kinesis Firehose Delivery Stream. Ruft man die Kinesis Console zum ersten Mal auf, kann man mit der Schaltfläche „Create delivery stream“ einen passenden Assistenten starten.
Dieser leitet in vier Schritten durch die Konfiguration des Delivery Streams, wobei wir nach Eingabe eines „Delivery stream name“ im Schritt 1 für alle weiteren Einstellungen bis Schritt 3 im Wesentlichen die Voreinstellungen übernehmen und jeweils auf „Next“ klicken.
Das bedeutet im Schritt 1, dass „Source“ auf „Direct PUT or other sources“ steht, um Records über die Firehose-PUT-API zu senden, und dass im Schritt 2 „Process records“ keine weitere Transformation der Records erfolgt („Record transformation“ = Disabled, „Record format conversion“ = Disabled). Erst im Schritt 3 „Choose destination“ verweisen wir auf das oben erstellte S3-Bucket. AWS Firehose unterstützt alternativ aber auch „Amazon Redshift“, „Amazon Elasticsearch Service“ oder „Splunk“.