Amazon SageMaker ist ein von AWS vollständig verwalteter Service, der den gesamten Workflow von Machine Learning abdeckt. In dieser Beitragsreihe befassen wir uns mit der grundlegenden ML-Thematik und dem Erstellen von Jupyter-Notebooks unter SageMaker.
Machine Learning (ML) bedeutet allgemein, dass der Computer Zusammenhänge aus Daten extrahiert. Das können sehr einfache aber auch äußerst komplexe Zusammenhänge sein. Das Extrahieren solcher Zusammenhänge kann, muss aber nicht zwangsläufig durch Deep Learning (neuronale Netze) erfolgen.
Hierbei taucht häufig auch der eher schwammig definierte Begriff „Artificial Intelligence“ (AI), Sprich Künstliche Intelligenz (KI) auf. Dieser bedeutet zunächst ebenfalls nur, dass der Computer mögliche Zusammenhänge aus Datenbeständen erkennt. Allerdings geht es bei AI primär darum, auf Basis der erkannten Zusammenhänge gezielte Entscheidungen zu treffen.
Hierbei unterscheidet man noch zwischen „Starker und Schwacher KI“. Starke KI kommt letztendlich dem menschenähnlichen Denken nahe – wobei es bisher noch nicht gelungen ist, sie in Software zu realisieren. Schwache KI ist bei einzelnen spezifischen Fähigkeiten wie z. B. der Bilderkennung oder künftig dem autonomen Fahren dem Menschen überlegen. Allerdings kann eine KI, die ein Fahrzeug steuern kann, keineswegs menschenähnlich denken.
Unter Deep Learning versteht man hingegen eine ganz spezifische Form schwacher KI, die als neuronales Netz realisiert ist. Das Wort „Deep“ spielt darauf an, dass es in einem neuronalen Netz normalerweise mehrere Schichten hintereinander gibt, die mit miteinander vernetzten Neuronen bestückt sind. Ebenfalls häufig im ML-Kontext verwendet wird der der Begriff „Natural Language Processing“. Hierbei geht es nur darum, dass eine Software natürliche Sprache verarbeiten kann. Ob dies mit Hilfe eines neuronalen Netzes passiert oder mit einem anderen Modell ist grundsätzlich egal.
Zusammenfassend kann man ML als Oberbegriff für bestimmte Technologien wie Deep Learning sehen. Allerdings wird in der angewandten Praxis meist dann von Machine Learning gesprochen, wenn keine neuronalen Netze im Spiel sind, während der Begriff Deep Learning immer dann verwendet wird, wenn Machine Learning mit neuronalen Netzen realisiert werden soll. Der Begriff Neuronales Netz wird in der Regel synonym für Deep Learning verwendet, während bei AI immer im Vordergrund steht, auf Basis z. B. mittels Deep Learning gewonnenen Erkenntnisse, Entscheidungen zu treffen oder weitere Aktionen einzuleiten.
Man kann sich dem Thema Deep Learning in AWS grundsätzlich von zwei Seiten nähern. Man kann z. B. das Funktionsprinzip neuronaler Netze, deren Konzeption, Aufbau, Training und Validierung vom Grundsatz her verstehen und mit entsprechenden Software-Methoden modellieren. Hierzu sind Programmiersprachen wie Python, R,oder Erlang besonders geeignet.
Python beispielsweise bringt sehr mächtige Bibliotheken zu diesem Zweck mit, z. B. Numpy, Pandas, Matplotlib, SciKitLearn, NLTK oder das von Google initiierte TensorFlow. Als Programmiersprache für Data Science ist Python quasi der ideale Kompromiss zwischen der Sprache R, die sich schwerpunktmäßig auf Datenanalyse und -visualisierung konzentriert, und Java. Diese Flexibilität bedeutet, dass Python als ein einziges Tool fungiert, dass einen kompletten Workflow zusammenführen kann.
Bevor wir uns also in den nächsten Teilen ausführlich mit dem Aufbau neuronaler Netze in Python, den Trainings- und Lern-Prinzipien befassen, wollen wir die Kerze zunächst einmal am „anderen Ende“ anzünden und demonstrieren, wie schnell und einfach sich ML-Modelle mit einem verwalteten Dienst wie Amazon SageMaker entwickeln, bereitstellen, trainieren und validieren lassen. Hierzu sollte man allerdings mit IPython bzw. Jupyter Notebooks vertraut sein, die wir in unserem Artikel vorgestellt haben.
Mit Amazon SageMaker lassen sich Machine-Learning-Modelle in der Regel zu geringeren Kosten und weitaus schneller in der Produktion bringen, als durch Bibliotheken wie Tensor Flow in Python. Der SageMaker-Service kennzeichnet und präpariert relevante Daten, wählt einen Algorithmus aus, trainiert und optimiert das Modell, passt es für die Bereitstellung an, trifft Voraussagen und ergreift ggf. Maßnahmen.
Freundlicherweise stellt AWS in seiner SageMaker-Dokumentation ein umfangreiches Einführungs-Tutorial zur Verfügung, dass u. a. Grundlage dieses Artikels bildet und zeigt, wie man einem einfach Bild-Klassifikator bereitstellt und mit frei zugänglicher Muster-Trainingsdaten trainiert und validiert.
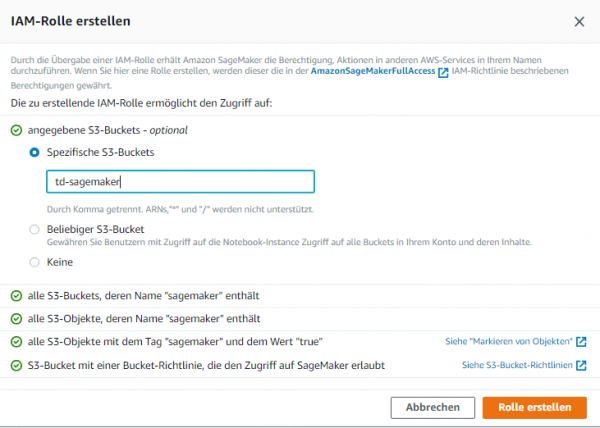
Dazu benötigen wir ein zuerst ein S3-Bucket. Dieses dient dem Speichern von der Datasets, die wir als Trainingsdaten verwenden. Außerdem speichern wir hier die Modellartefakte. Amazon SageMaker benötigt die Berechtigung für den Zugriff auf das Bucket. Dies lässt sich wie üblich am einfachsten durch Einrichten einer IAM-Rolle bewerkstelligen.
Die IAM-Rolle ruft automatisch Berechtigungen für den Zugriff auf Buckets ab, deren Name „sagemaker“ enthält und verwendet dazu das Richtliniendokument „AmazonSageMakerFullAccess“, welches Amazon SageMaker an die Rolle anfügt. Verwendet man in der Rolle dagegen eine S3-Bucket-Richtlinie, die die Server-Prinzipal-Berechtigung „S3FullAccess“ gewährt, muss der Name des Buckets nicht zwingend „sagemaker“ enthalten. Die Rolle kann aber im Verlauf der Bereitstellung einer SageMaker-Notebook-Instanz automatisch erstellt werden.
Im nächsten Schritt erstellen wir eine SageMaker-Notebook-Instanz auf EC2. Eine solche Instanz ist also nichts anderes, als eine vollständig verwaltete EC2-Compute-Instance für maschinelles Lernen, auf der die Jupyter-Notebook-App ausgeführt wird. Diese Notebook-Instanz wird dann zum Erstellen und Verwalten sämtlicher Jupyter-Notebooks verwendet, um Daten vorbereiten und verarbeiten zu können sowie für das Bereitstellen und Trainieren der einzelnen Machine-Learning-Modelle.
Das Erstellen einer Notebook-Instanz erfolgt komfortabel aus der SageMaker-Console mit einem Klick auf „Notebook-Instance erstellen“. Im Abschnitt „Notebook-Instance-Einstellungen“ hinterlegen wir mindestens einen Namen und die Instanz-Größe; klappt man „Zusätzliche Konfigurationen“ auf, kann man noch die Volume-Größe bestimmen.
Im Prinzip handelt es sich bei den Notebooks um gewöhnliche EC2-Instanzen, allerdings wird man diese ähnlich wie bei RDS nicht in der EC2-Conole finden. Notebook-Instanzen sind daher am Präfix „ml“ zu erkennen. Wir starten mit dem kostengünstigsten Typ „ml.t2.medium“ und 5 GB (Gigabyte) Storage.