Als echter verteilter Objektspeicher kennt Amazon S3 kein richtiges Dateisystem. Mit dem AWS Command Line Interface lassen sich S3-Ressourcen aber recht komfortabel erstellen, verwalten und verwenden sowie Vorgänge automatisieren.
Amazon S3 ist ein Objektspeicher zum Speichern und Abrufen beliebiger Datenmengen und Datenarten aus nahezu beliebigen Speicherorten. Dies können Websites und mobile Apps sein oder auch Unternehmensanwendungen sowie Daten von IoT-Sensoren und -Geräten. S3 dient bei Bedarf auch als Archiv für EBS-Snapshots oder als Konfigurationsmanagement-Repositoryfür Chef (Rezepte) oder Puppet (Manifeste) und zum Aufnehmen von Code-Repositories aller Art.
Amazon S3 ist auf eine Haltbarkeit von 99,999999999 % ausgelegt und speichert Daten für Millionen von Anwendungen. Hinzu kommen umfassende Sicherheits- und Compliance-Funktionen und eine direkte Abfragefunktion, die es erlaubt, leistungsstarke Analysen an inaktiven Daten (Data-At-Rest) in S3 durchzuführen.
Was ist Amazon S3?
Als echter Internetspeicher wird S3 beinahe ausschließlich über seine umfassende REST-API über HTTP-Aufrufe und entsprechende Abfragen (PUT, COPY, POST, LIST, GET, DEL) angesprochen. Eine Ausnahme bildet lediglich die Möglichkeit, in der jeweiligen Virtual Private Cloud (VPC) einen S3-Endpunkt anzulegen. Dieser erlaubt es einem Service in der eigenen VPC wie z. B. einer EC2-Instanz, ohne Umweg über das Internet und damit kostenneutral und mit maximaler Performance auf ein S3-Bucket zuzugreifen.
Adressierung und Service-Limits
S3 ist ein echter verteilter Objektspeicher und kennt kein Dateisystem oder ähnliches, was durch das „S“ im Namen für „simple“ gekennzeichnet ist. Die oberste Ebene des Objektspeichers ist der „Bucket“ (z. Dt. Eimer), der sämtliche Objekte (Bilder, Texte, CSS-Dateien, Videos, Log-Dateien etc.) aufnimmt. Der gewählte Bucket-Name muss weltweit eindeutig sein, da der Namespace von S3 global ist, auch wenn der Scope von S3 immer die Region ist, in der der Nutzer den Bucket erzeugt.
Größenbeschränkungen gibt es keine, sieht man mal davon ab, dass pro Konto 100 Buckets erlaubt sind und ein Einzel-Objekt nicht größer als 5 Terabyte (TB) sei darf. Davon abgesehen kann ein Bucket beliebig groß werden. Der Zugriff erfolgt über den Schlüssel „https://s3.amazonaws.com/<Bucket>/<Objekt>“, wobei der gesamte Teil rechts des Buckets samt etwaiger Slashes (/) als „Objekt-Key“ interpretiert wird.
Das ist insofern von Bedeutung, als der Objektspeicher kein hierarchisches Dateisystem, also eine quasi flache Struktur besitzt. Der Nutzer kann also eine Quasi-Ordnerstruktur in den Objekt-Key abbilden, obwohl de facto keine Ordnerstruktur besteht. Bei https://s3.amazonaws.com/<Bucket>/Fotos/2017/Urlaub/IMAG0029.JPG ist der Objekt-Key z. B. „/Fotos/2017/Urlaub/IMAG0029.JPG“.
S3 Command Line Interface
Per AWS-CLI lassen sich Aufgaben im Zusammenhang mit S3 elegant automatisieren. In den folgenden Beispielen kopieren und/oder verschieben wir zunächst eine Anzahl von Dateien von bzw. hin zu einem S3-Bucket. Dazu muss zunächst ein S3-Bucket angelegt werden, wozu es entsprechender Berechtigungen bedarf. Abschließend richten wir eine automatische Synchronisation eines lokalen Verzeichnisses mit eine S3-Bucket ein.
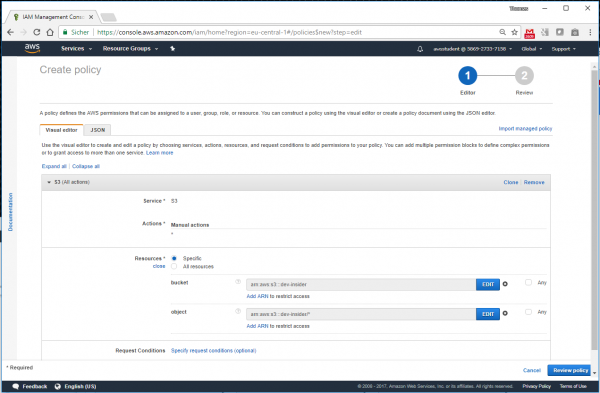
S3 kennt historisch bedingt drei verschiedene Ansätze zum Verwalten und Zuweisen von Berechtigungen: die klassischen, aber nur grob granular steuerbaren Bucket-ACLs sowie IAM-Richtlinien oder S3-Bucket-Richtlinien. Für dieses Beispiel erstellen wir der Einfachheit halber eine IAM-Policy mit dem Policy-Generator. Diese soll für das S3-Objekt „arn:aws:s3:::<bucket-name>“, sowie sämtliche Schlüssel darin „arn:aws:s3:::<bucket-name>/*“ vollen Zugriff auf sämtliche S3-Funktionen bieten.
Diese Policy können wir dann an eine ebenfalls neu zu erstellenden IAM-Rolle „S3FullAcess“ hängen, um damit eine neue EC2-Instanz zu instanziieren. Diese soll im folgenden Beispiel auf den Namen „ Processor“ hören und für die skizzierten Synchronisationsbeispiele herhalten. So haben wir in unserer Test-Instanz namens Processor eine fiktive Log-Datei erstellt, deren Einträge durch je einen Zeitstempel gebildet werden. Wir haben dazu folgendes einfaches Bash-Skript verwendet.
#!/bin/bash
while :
do
date +“%m-%d-%Y %T“ >> /home/ec2-user/timestamp.log
sleep 10
done
Lässt man das Skript mit …
./log-generator &
… permanent im Hintergrund laufen, erhält man im Zehn-Sekunden-Takt (sleep 10) frische Log-Einträge, was man mit
tail timestamp.log