AWS S3 stellt eine gute wenn nicht die perfekte Lösung für den Primärspeicher im Zuge einer Data-Lake-Strategie dar. In diesem Beitrag wollen wir uns der Umsetzung zuwenden. Dabei beginnen wir mit der Daten-Aufnahme, dem Data-Ingest.
Im Rahmen einer Datalake-Strategie sind mehrere Möglichkeiten vorstellbar, wie zu analysierende Daten nach AWS S3 gelangen. Das manuelle oder automatisierte Hochladen über das Internet über die S3-API ist nur für überschaubare Datenmengen praktizierbar. Alternativ können Nutzer verwaltete AWS-Services wie Snowball oder Snowmobile verwenden, um eine initialen Datenbestand in Petabyte-Größe initial in die Cloud zu bekommen.
Im Rahmen einer Data-Lake-Strategie ist dies sicherlich nur der Anfang. Weitere Daten werden dem Data Lake dynamisch hinzugefügt. Soll/muss dies in Echtzeit erfolgen, ist eine verwaltete Streaming-Lösung wie AWS Kinesis eine gute Wahl. Zuvor aber noch ein paar Gedanken zu AWS S3.
Metadaten
AWS S3 ist als Objektspeicher per se erst einmal ein „dummer“ Speicher. Da S3 kein Dateisystem zugrunde liegt, das als Vehikel zum Speichern/Zuordnen von Meta-Informationen dienen könnte, muss sich der S3-Nutzer selbst um das Anreichern des Datenspeichers mit Meta-Informationen kümmern. AWS S3 verwaltet dazu für jedes in einem Bucket gespeicherte Objekt einen Satz Systemmetadaten und verarbeitet diese Systemmetadaten nach Bedarf, wie z. B. das Erstellungsdatum eines Objekts und seine Größe. Diese Informationen dienen der Objektverwaltung.
Es gibt allerdings zwei Kategorien von Systemmetadaten: Metadaten wie das Erstellungsdatum eines Objekts werden vom System gesteuert, d. h. nur Amazon S3 selbst kann den betreffenden Wert ändern. Beispiele für steuerbare Meta-Informationen sind z. B. die für das Objekt konfigurierte Speicherklasse oder ob für das Objekt eine serverseitige Verschlüsselung aktiviert ist. Ist ein Bucket beispielsweise als statische Website konfiguriert, ist die Webseite ein Objekt im Bucket. Möchte der Nutzer beispielsweise irgendwann den Zugriff auf eine andere Seite oder zu einer externen URL umleiten, speichert S3 den Wert für die Seitenumleitung ebenfalls als Systemmetadaten.
Erstellt der Nutzer neue Objekte, kann er die Werte dieser Systemmetadaten konfigurieren oder sie nach Bedarf aktualisieren. Folgende Tabelle zeigt eine Auswahl möglicher Metadaten, ergänzt jeweils im einen Hinweis auf die „Steuerbarkeit“ durch den Benutzer.
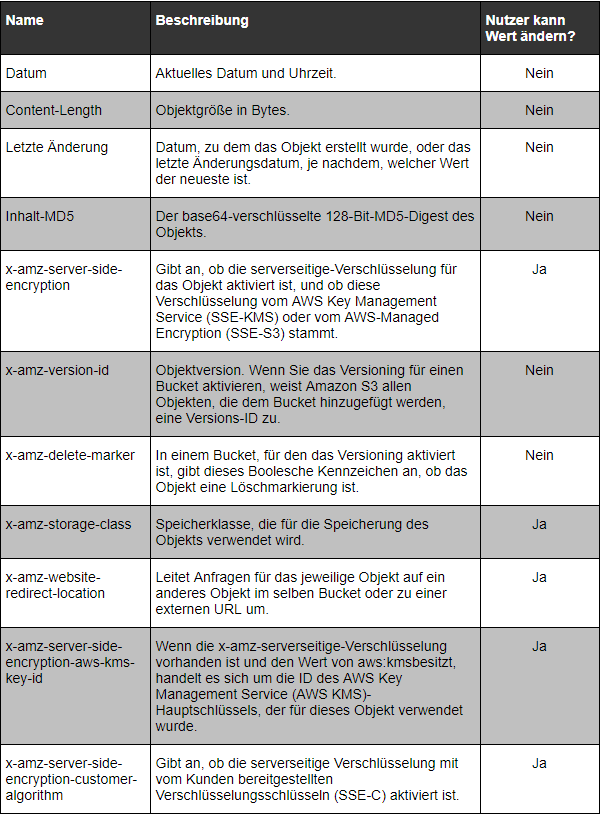
In Python ist es vergleichsweise einfach, auf S3-Metadaten zuzugreifen bzw. diese zu verändern:
key.put(Metadata={‚meta1‘: ‚Das ist meine Metadaten-Wert‘})
print(key.metadata[‚meta1‘])
Angenommen Sie arbeiten in Python mit S3-Objekten, die bekanntlich durch ihren Object-Key im betreffenden Bucket identifiziert werden. Im folgenden Beispiel ist die S3-Versionierung aktiv, es gibt also Revisionen jedes Objektes. Sie können wie folgt sämtliche Object-Keys abrufen und aus den Objekt-Metadaten den Typ „revisions“ extrahieren.
backups = {}
for key in bucket:
key = bucket.get_key(key.name)
backups[key.name] = key.get_metadata(‚revision‘)
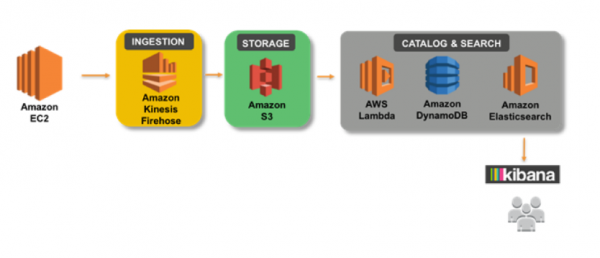
Darüber hinaus braucht man im Rahmen einer Data-Lake-Strategie vor allem „inhaltsbezogene“ Meta-Daten, denn ohne einen vernünftigen Index, weiß am Ende niemand mehr, welche Daten im Data Lake gespeichert sind, sodass man auch nicht nach ihnen suchen kann.
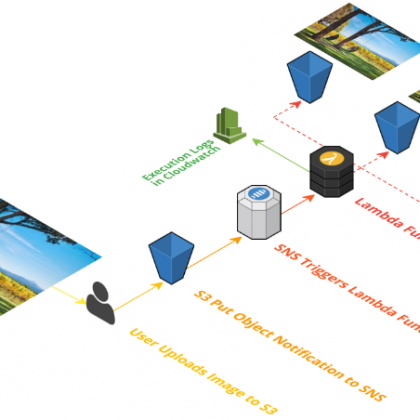
Um dies Problem zu lösen, kann man sich die Benachrichtigungsfunktion von S3 zunutze zu machen. Diese erlaubt es nicht nur dem Benutzer, sich benachrichtigen zu lassen, wenn ein neues Objekt hochgeladen oder gelöscht wird, sondern kann z. B. auch einen automatisierten Eintrag in einer DynamoDB-Table erzeugen (Index) oder eine beliebige andere Lambda-Funktionen zur Erweiterung der Intelligenz des Datalakes anstoßen.
Man könnte sogar noch einen Schritt weiter gehen und Suchfelder aus den Daten extrahieren, die man z. B. in AWS Elastic Search zugänglich macht, um die Suchfelder mit einer Volltextsuche durchsuchen zu können. Bevor wir das im nächsten Teil dieses Workshops tun, noch ein paar Worte zur Sicherheit.